
As part of my ongoing adventures into eBPF, i’ve published a new tool on GitHub - Minderbinder.
Minderbinder uses eBPF to inject failures into running processes. It is essentially the network vershitifier with a configuration loader bolted on the front, and generalized out so that it supports other sorts of chaos experiments too. Also, and perhaps most importantly, there’s a terminal UI!
You can configure Minderbinder with a short yaml document - each sort of
experiment has a subsection, where you can list multiple interventions. Here’s
how we configure a system call failure - openat, when used by curl, will start
returning no such file or directory 100ms after the process starts. The delay
gives the process a chance to start properly before starting to break things -
openat is needed to map in all of the shared libraries at process startup.
agents_of_chaos: syscall: - name: break_curl_openat syscall: openat ret_code: -2 # NOENT / no such file or directory targets: - process_name: curl delay_ms: 100 failure_rate: 100 # % probability a call will fail after the delay
outgoing_network: - name: break_wget_network targets: - process_name: wget delay_ms: 100 # Milliseconds. In this case, 100ms should be enough to get a DNS request through for the endpoint, before breaking the actual transfer to the HTTP server failure_rate: 100The ret_code is the return value Minderbinder should make the system call
return. By convention, -ve values returned from system calls are treated by
glibc as errors, which inverts their value and puts them into the thread-local
errno. When we look up the errno we want to return, we need to flip the sign
when we return it from kernel space.
Like the it’s predecessor, Minderbinder also continues to support traffic control based outgoing-packet dropping but this time nicely wrapped up in the configuration loading framework; you can see an example of this in the GitHub repo.
Structure
There’s a lot more eBPF C-land code here, and i’ve made an effort to break things up
sensibly so that it’s easier to maintain and quickly grok
what’s going on. It seems that there is no easy way of having multiple
my_ebpf_entrypoint.c variants hooked up to a single ebpf-go app, so i’ve
followed a pattern i’ve spotted in other projects, breaking the implementation
up into module-specific header files. I’m not super satisfied with this, and
would be happy to be told there’s a better way - reach out if you know one!
Beyond that, I’ve split each module into a x.h and an x_maps.h.
This makes it easier to see what the interface of e.g. the system call module is.
How does it work?
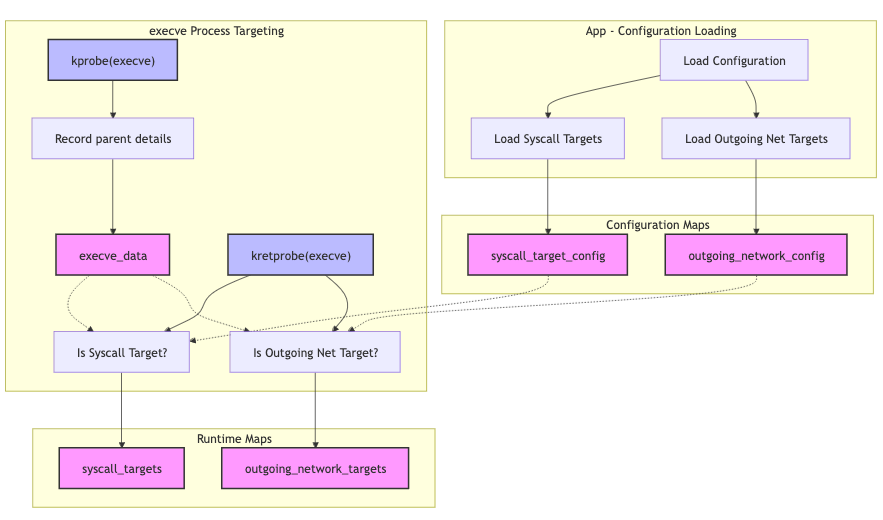
We attach a kprobe and a kretprobe to execve in order to catch processes being
launched. If processes match configured targets (e.g., “this is an instance of
curl”) passed in from user-space, we add them into the corresponding runtime
maps - here we are associating the configuration loaded the YAML with process
IDs we have seen launch we are interested in:
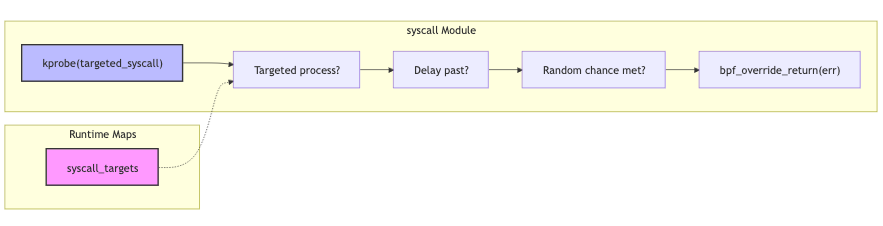
The system call failures are injected by attaching a kprobe to each system
call configured - here we can use bpf_override_return to return an error code
back to user space, effectively short-circuiting the invocation of the system
call handler. I spent some time trying to achieve this using tracepoints - as
they should represent a stable interface to the kernel - but it does not appear
possible to mutate the system call here. Whenever the targeted system call is
made, we check if the PID is contained in the syscall_targets:
The outgoing network failures are injected using the traffic control subsystem,
by implementing a TC filter using eBPF. TC was traditionally something of a
fixed-function beast, which let us use pre-configured strategies to rank traffic
priorities, as well as drop traffic. Here, Minderbinder uses an eBPF program to
pick up traffic from sockets we have marked earlier on when a targeted process
creates them, and randomly use TC_ACT_STOLEN to drop traffic, while indicating
to the caller that the traffic was successfully transmitted - a nice way of
simulating ordinary packet loss!
Long-Term Vision
From a software engineering perspective, I’m super enthusiastic about anything that can make it easier to run more complete tests earlier in the development lifecycle. Kicking the testing can down the road and leaving anything around the outside of a service for end-to-end testing is a nightmare, because E2E tests are flaky, difficult to write, difficult to debug, and costly. Component testing
- “start this service up, and stub out everything downstream” is a great middle ground, but here too the fields are not only green - stubbing everything out and then painstakingly injecting failures is time consuming, and sprawls out with your downstream service count.
Here I think something like Minderbinder - a generic tool for injecting targeted
failures into processes - could be created as a common, language-independent
test supporting tool. You’d fire up your test suite, inject some generic
“say yes” HTTP server to succeed all the downstream calls, and then use a
language-specific binding to wrap each test in a failure configuration -
withFailureConfig(x), test -> { /* do test */ }. The need to go and reach into
each unit of code to inject stubs to e.g. make it possible to inject a disk IO
failure is then removed - because the eBPF wrapping the test execution would
simply watch the process under test, and break the disk IO when it hits the
kernel.
I don’t think this is the be-all-and-end-all of component testing - for instance, the effort involved in teasing out interfaces to stub has a beneficial effect on modularity, but it would be another tool in the toolbox to make it easier to test complex “external failures” on processes quickly, decreasing the volume of failures we wait for our E2E suite to pick up.
Anyhow …
It’s early days! If you’re interested in eBPF-mediated-chaos, go have a play with the code and let me know what you think.